
Suggesting product prices for e-commerce company
This was my first project when I started in Data back in 2018, I was able to learn many concepts on the way.
Dataset
Mercari website data
Online shopping is increasing at a rapid rate with companies like Amazon Inc., eBay, Newegg, etc. Companies have to deal with several kinds of items from various retailers at various scales as there are many features that could affect the price. Hence we try to suggest the price to the retailers by using the history of the past products sold.
We are using a dataset from a online website which has about 1.5 million items.
One of this product costs $49 and other costs $112.Looking at such type of products can you guess which product costs which one?
Item A - Puma women’s Long sleeve , turtle neck tee, size L, Great condition
Item B - Vince long-sleeve turtle, neck tee, size L, Great condition
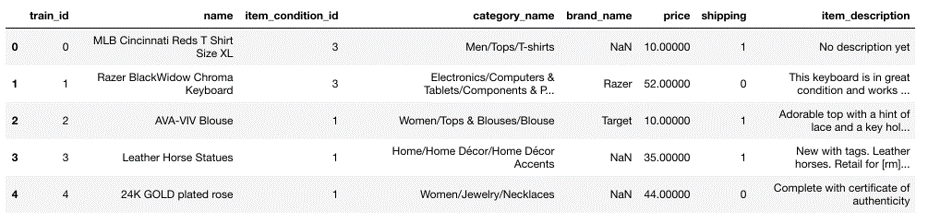
Dataset has three main components - Item name, Item Category and Item description. It also has supporting features like condition of item and brand of item.
Goal : To select algorithms that can predict the product prices using the features like Item description and Item category looking at the historical data.
from nltk import word_tokenize
from nltk.stem.porter import PorterStemmer
import numpy as np # linear algebra
import pandas as pd # data processing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import LabelBinarizer
from sklearn.decomposition import TruncatedSVD
import math
import scipy
#ptrain = pd.read_csv('trainn.tsv', sep='\t')
brands = 6500
mindf = 2
max_desc = 100000
def tsv_split(filename, t_size):
train = pd.read_csv(filename, sep='\t')
return train_test_split(train,test_size=t_size,random_state=42)
stemmer = PorterStemmer()
def StemTokenizer(tokens):
return [stemmer.stem(token) for token in tokens]
def Stemmer(text):
word_tokens = word_tokenize(text.lower())
return StemTokenizer(word_tokens)
def rmsle(y, y_pred):
assert len(y) == len(y_pred)
to_sum = [(math.log(y_pred[i] + 1) - math.log(y[i] + 1)) ** 2.0 for i,pred in enumerate(y_pred)]
return (sum(to_sum) * (1.0/len(y))) ** 0.5
Exploratory Data Analysis
In order to understand the dataset and to identify any obvious patterns we use EDA in the first phase of Data Modeling.
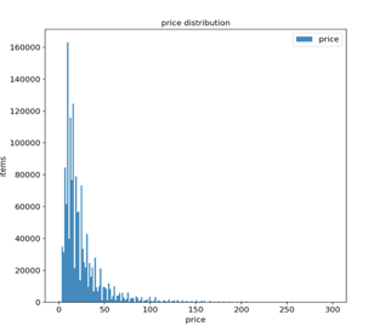
Data Preprocessing & cleaning
This data set had mostly categorical features which would need thorough data cleaning and transformation in order to extract necessary features. Removed rows with price = 0 in our case and handled missing values so that we don’t encounter errors in modeling phase.
def clean_missing(dataset):
dataset['name'].fillna('missing', inplace=True)
dataset['brand_name'].fillna('missing', inplace=True)
dataset['item_description'].fillna('missing', inplace=True)
dataset['shipping'] = dataset.shipping.fillna(value=0)
dataset.loc[~dataset.shipping.isin([0,1]), 'shipping'] = 0
dataset['shipping'] = dataset.shipping.astype(int)
dataset['item_condition_id'] = dataset.item_condition_id.fillna(value=1)
dataset.loc[~dataset.item_condition_id.isin([1,2,3,4,5]), 'item_condition_id'] = 1
dataset['item_condition_id'] = dataset.item_condition_id.astype(int)
dataset["category_name"] = dataset["category_name"].fillna("Other").astype("category")
dataset["brand_name"] = dataset["brand_name"].fillna("unknown")
pop_brands = dataset["brand_name"].value_counts().index[:brands]
dataset.loc[~dataset["brand_name"].isin(pop_brands), "brand_name"] = "Other"
dataset["item_description"] = dataset["item_description"].fillna("None")
dataset["item_condition_id"] = dataset["item_condition_id"].astype("category")
dataset["brand_name"] = dataset["brand_name"].astype("category")
return dataset
Feature engineering
Transform Categorical features to vectors using Count vectorizer, Label Binarizer, and TF-IDF and one hot encodingtechniques
Concepts:
- Feature Extraction
- Text Analytics
- Bag of Words
- Tokenization
- TF-IDF
- Label Binarizer vs one hot encoder
Logarithmic transformation to smooth long tailed or skewed data to more of a normal distribution to be used in regression setting.
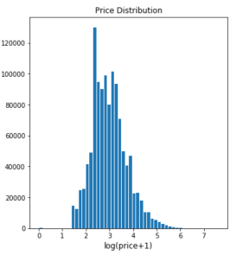
def count_vectorize(df, category):
cvect = CountVectorizer(tokenizer=Stemmer , stop_words = 'english', min_df=mindf)
return cvect.fit_transform(df[category])
def tfidf_vectorize(df, category):
tfidfvect = TfidfVectorizer( tokenizer=StemTokenizer,
max_features = max_desc,
ngram_range = (1,3),
stop_words = "english")
return tfidfvect.fit_transform(df[category])
def label_binarize(df, category):
labelbinar = LabelBinarizer(sparse_output=True)
return labelbinar.fit_transform(df[category])
df_trains = pd.read_csv('trainModel.tsv', sep='\t')
df_test = pd.read_csv('testModel.tsv', sep='\t')
df_train=df_trains.sample(frac=0.3,random_state=200)
df_validation=df_trains.drop(df_train.index)
del(df_trains)
df_main = pd.concat([df_train,df_validation, df_test], 0)
nrow_train = df_train.shape[0]
nrow_validation = df_validation.shape[0]
y_train = np.log1p(df_train["price"])
y_validation = np.log1p(df_validation["price"])
print("transforming...")
print("handling missing values..")
df_main = clean_missing(df_main)
print(df_main.memory_usage(deep = True))
print("Name Encoders using CountVectorizer")
X_name = count_vectorize(df_main, "name")
print("Category Encoders using CountVectorizer")
unique_categories = pd.Series("/".join(df_main["category_name"].unique().astype("str")).split("/")).unique()
X_category = count_vectorize(df_main, "category_name")
print("Description encoders using TfidfVectorizer")
X_descp = tfidf_vectorize(df_main, "item_description")
print("Brand Name Encoders using LabelBinarizer")
X_brand = label_binarize(df_main, "brand_name")
print("Dummy Encoders")
X_dummies = scipy.sparse.csr_matrix(pd.get_dummies(df_main[[
"item_condition_id", "shipping"]], sparse = True).values)
X = scipy.sparse.hstack((X_dummies,
X_descp,
X_descp,
X_brand,
X_category,
X_name)).tocsr()
Modeling
Why Regularization ? : As the data has items with price $ 3- 2000, it shows lot of variation with price. We have lot of information which is essentially just noise hence to overcome the problem of overfitting we choose regularization. Regularization allows shrinking of parameters which helps with collinearity and also reduces model complexity.
Concepts:
from sklearn.ensemble import RandomForestRegressor
#the different regressions we used
model = Ridge(alpha=0.8, solver = "lsqr", fit_intercept=False)
#model = Lasso(alpha=0.8)
X_train = X[:nrow_train]
#model = RandomForestRegressor(n_estimators= 300, max_features= 'sqrt', n_jobs= -1, max_depth=16, min_samples_split=5, min_samples_leaf=5)
model.fit(X_train, y_train)
print('Predicting validation set')
X_validation = X[nrow_train:(nrow_train+nrow_validation)]
preds_validation = model.predict(X_validation)
print('RMSLE on validation set',
rmsle(np.expm1(np.asarray(y_validation)), np.expm1(np.abs(preds_validation)) ))
Reference: Kaggle Competition